|
|
4
|
APPENDICES
|
|
|
|
|
4.1
|
|
Appendix A: Diacritics
|
|
|
|
|
|
4.1.1
|
|
|
Diacritics in AAT, TGN, ULAN, IA, and CONA
|
|
|
|
|
|
4.1.1.1
|
|
|
Unicode
For the the Getty Vocabularies, all data, including terms and scope notes, must be contributed in Unicode (Unicode Consortium, Unicode 15.1 (2023), which is synchronized with ISO/IEC 10646). The Vocabulary data is published in Unicode.
|
|
|
|
|
|
4.1.1.2
|
|
|
Legacy data
You may encounter versions of the Vocabulary data that use legacy codes for diacritics. The following chart lists the codes used to indicate diacritics
in the legacy Vocabulary data. Each code consists of the dollar sign
($) followed by two numbers. This code is placed before (in
front of) the letter to which the diacritical mark applies.
The same code can be applied to multiple letters. For example,
if an acute accent should be applied to an a (á),
it is recorded as $00a; if an acute accent should
be applied to an e (é), it is recorded as $00e.
In some cases, the code means that two diacritics are placed
over the same character (e.g., $30). In other isolated cases,
the code applies to two adjacent characters (e.g., $57, a
digraph).
|
|
|
|
|
|
4.1.2
|
|
|
Legacy Diacritical Codes: Quick Reference
|
|
|
|
|
|
|
|
|
|
4.1.3
|
|
|
Diacritical Codes: Full List
|
|
|
|
|
|
|
| |
|
|
Please consult the full
list of diacritics and Unicode mapping as necessary.
|
|
|
|
|
|
|
|
Last updated 26 March 2024
Document is subject to frequent revisions
|
|
|
|
|
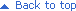
|
|
|
|
|
|
|
|